AI는 마치 현대판 프로메테우스의 불과 같다. AI는 인류에게 막대한 효용과 부를 가져다줄 것이지만, 인류는 AI의 발전 과정에서의 부작용을 최소화하며 이를 잘 다뤄야할 것이다.
데이터 프라이버시 문제는 AI 기술이 야기하는 대표적인 부작용들 중 하나이다. AI 모델의 학습과 추론에는 개인정보와 같은 민감한 정보들이 필연적으로 활용될 수 밖에 없는데, 닐리언(Nillion)은 이를 해결하기 위해 암호화 데이터 연산 기술과 블록체인을 활용하여, 사용자들이 데이터가 안전하게 보호받고 활용될 수 있도록 한다.
닐리언 팀은 크립토 산업에서 비지니스와 연구에서 모두에서 뛰어난 백그라운드를 가진 몇 안되는 팀이다. 닐리언은 공격적인 비지니스와, 뛰어난 연구 실력을 기반으로 인터넷의 블라인드 컴퓨팅 레이어를 빌딩하는 것을 목표로 한다.

프로메테우스가 신의 불을 훔쳐 인간에게 가져다준 순간, 인류는 문명의 빛과 어둠을 동시에 품게 되었다. 그 불길은 인류에게 문명을 선사했지만, 동시에 신들의 분노를 샀고, 프로메테우스는 영원한 형벌을 받게 되었다.
앞으로 인류에게 가장 중요한 기술이 무엇이냐고 질문 받았을 때, 나는 한 치의 망설임 없이 AI라고 답할 것이다. 물론, 인류에게는 의식주, 건강, 에너지와 관련된 기본적인 산업 및 기술이 필수적으로 필요하지만, AI는 모든 종류의 발전을 전례없는 속도로 가속화할 수 있다는 점에서 가장 핵심 기술이 될 것이다.
이는 이미 현재 AI 산업의 규모와 발전 속도가 증명하고 있다. 2022년 ChatGPT 서비스 이후로 AI 산업의 불꽃은 꺼질 기미가 보이지 않는다. 조사 기관에 따라 다르지만 불과 ChatGPT가 공개된 후 2년 후인 2024년에 AI 시장의 규모는 수 천억 달러로 성장했으며, 2030년엔 수 조 달러로 성장할 것으로 예상된다. 특히, 최근 OpenAI는 무려 $40B의 펀딩 라운드를 발표하며, AI 산업이 얼마나 거대하고 빠르게 발전하고 있는지 다시 한 번 증명했다.
구글, 메타, 마이크로소프트, 아마존 등 빅테크 기업들은 이미 알고리즘 개발, 서버 확장, 전기 설비 등 AI와 관련된 다양한 분야에 역사적으로 전례없는 막대한 규모의 투자금을 쏟아붇고 있으며, 기업 수준에서 더 나아가 AI 산업은 국가 차원에서 전략적으로 융성하고 있다. 다음 패권국가가 결정되는 기준은 AGI의 발명이 될 것이며, 최근 미국과 중국이 AI 산업을 육성하는 것을 보면 마치 냉전 시대의 군비경쟁을 떠올리게 한다.
하지만 모든 기술 발전에는 명과 암이 있는 법이다. 어떠한 종류의 기술이 되었든, 보통 부작용은 기술 발전의 뒤를 따른다. 프레온 가스의 개발자는 이것이 오존층을 파괴할지 몰랐을 것이고, 핵물리학자들은 핵폭탄이 수 많은 사상자를 발생시킬 줄 몰랐을 것이다.
AI도 마찬가지이다. AI는 인류에게 막대한 생산성과 부를 안겨줄테지만, 여기에는 우리가 AI를 잘 컨트롤할 수 있다는 전제가 필요하다. AI 발전에서 자주 거론되는 대표적인 부작용 중 하나는 데이터 프라이버시이다.
AI 모델을 학습시키기 위해선 방대한 데이터 수집이 필수적인데, 이 중에선 개인정보나 민감 정보가 다수 포함될 수 있다. 만약 AI 모델의 개발사가 프라이버시를 소홀히 하게 되면 윤리적 문제는 물론, 규제 준수 위반으로 인한 법적 제재 위험이 있다. 따라서 AI 모델을 개발하는 빅테크 기업들은 고객 데이터를 어떻게 관리하고 사용하는지 명시하고 있다.
하지만 주목해야할 것은, OpenAI, 구글, 앤쓰로픽(Anthropic) 등 대부분의 LLM을 개발하는 기업들이 모델의 성능 향상을 위해 사용자가 제공하는 입력, 파일 업로드, 피드백 등 개인 정보를 수집한다는 것이다. 물론, 사용자가 데이터 관리 옵션을 통해 데이터를 공유하지 않거나, 혹은 원한다면 데이터 삭제를 요청할 수 있다. 하지만, 기본적으로 사용자들이 LLM과 상호작용하는 모든 데이터가 기업에 활용되는 것은 사람들이 잘 인지하지 못하고 있는 큰 문제이다.
실제로 이탈리아 데이터보호청은 2023년 3월 ChatGPT 서비스가 개인정보 보호 규정을 위반할 소지가 있다고 판단하여 일시적 서비스 중단 조치를 내리고 조사를 진행하기도 했다. 최근 여러 국가들이 중국에서 개발된 딥시크의 사용을 제한하거나 금지하는 조치를 취한 것도 데이터 프라이버시 보호 차원의 조치이다.
위에서 언급한 기업들의 경우 그나마 데이터 프라이버시 정책을 잘 지키는 편이지만, 기업이 고객들의 데이터를 함부로 사용한다거나, 혹은 기업들이 고객의 데이터를 안전하게 관리하고 사용한다고 하여도 데이터 유출과 같은 단일점 실패의 문제도 있다.
전자의 예시로는 캠브리지 애널리티카의 사례가 있다. 2018년에 영국의 컨설팅 기업 캠브리지 애널리티카는 페이스북을 통해 수 천만 명의 개인정보 데이터를 동의 없이 수집하여 정치 캠페인에 활용하였고, 이는 AI 기반 데이터 분석이 개인의 정치적 성향을 프로파일링하고 선거에 영향을 미친 사례로 큰 파장을 일으켰다.
후자의 예시로는 ChatGPT 개인정보 유출 사건이 있다. 2023년 3월에 ChatGPT는 시스템 버그로 인해 일부 사용자의 대화 내역 제목과 결제 관련 개인정보가 다른 사용자에게 노출되는 사고가 발생했다. 이는 위에서 언급한 이탈리아 데이터보호청이 OpenAI 서비스를 일시 중단하고 조사를 진행하게 되는 계기가 되었다.
이처럼 AI 데이터 프라이버시는 AI 산업의 발전을 위해 제쳐두고 소홀히할 주제가 아니라, 개인의 보안에 더 나아가 각 정부의 안보가 달려있는 아주 중요한 요소이다.
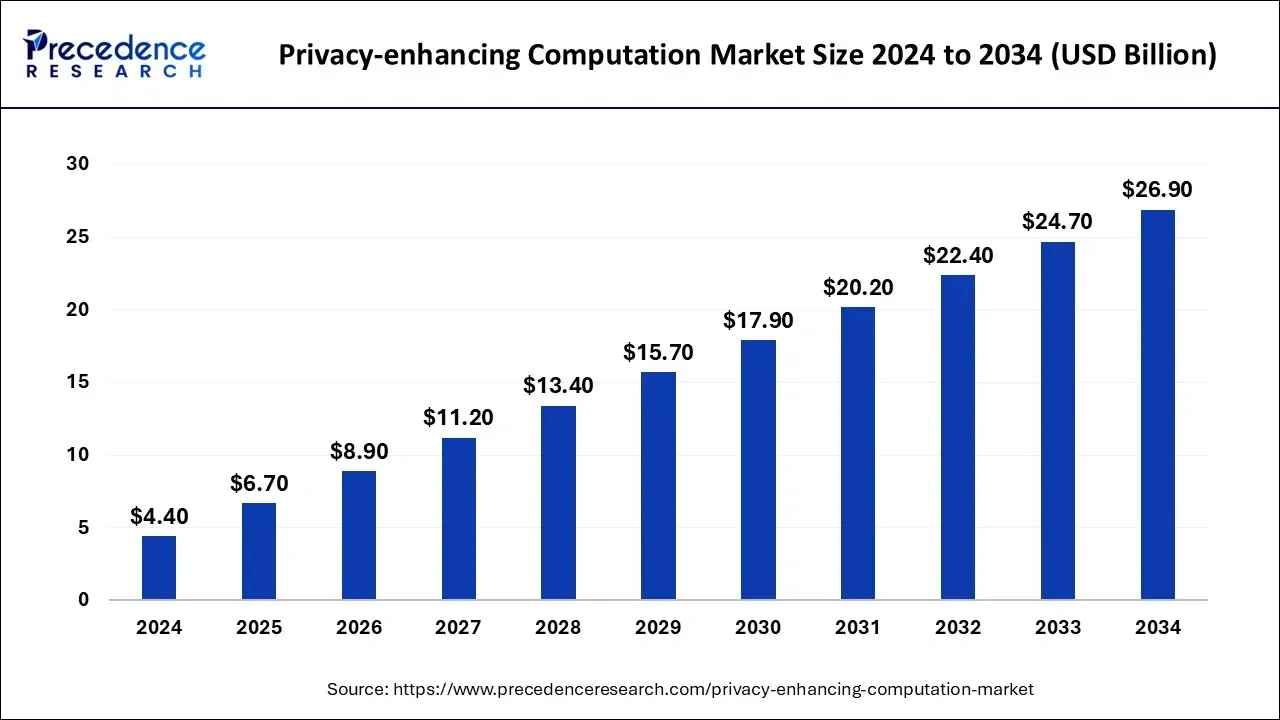
Source: Precedence Research
AI 산업이 전반적으로 뜨거운 관심과 막대한 투자금이 쏟아지는 만큼, AI 데이터 프라이버시에 대한 수요도 빠르게 증가하고 있다. Precedence Research에 따르면 동형암호, MPC, 연합학습과 같이 프라이버시 강화 연산 기술 시장의 규모는 2024년 약 44억 달러 규모에서 연 평균 19.9%의 성장률로 확대되어, 2034년 경에는 약 269억 달러 규모에 이를 것으로 전망한다.
과학 기술의 역사를 되짚어보면, 기술 발전 초기 단계에는 부작용보다는 효용을 극대화 하기 위해 자본이 투입되지만, 기술이 어느정도 성숙해지고 난 후에는 부작용(e.g., 지구온난화)를 해결하기 위한 산업이 빠르게 성장하는 것을 볼 수 있다. 이러한 맥락에서 프라이버시 보호 솔루션 시장은 앞으로 더 중요해질 것이다. 전문가들은 가까운 미래에 프라이버시 보호 기술의 적용이 AI 서비스의 신뢰 확보에 필수조건이 될 것으로 전망하며, 이는 지속적인 고성장세를 이어갈 것이다.
데이터 프라이버시를 지키기 위한 솔루션을 살펴보기 전에, 우선 각 정부들이 이와 관련하여 어떠한 정책 및 이니셔티브를 전개하는지 살펴보자. 이러한 예시들은 AI 산업 내에서 데이터 프라이버시의 중요성을 강조하는 사례들이다.
EU AI Act: 2024년 8월, EU에서 세계 최초로 일부 발효된 AI 종합 법률로, 안전하고 신뢰할 수 있는 AI를 촉진하고, 기본권과 윤리를 존중하도록 하는 것을 목표로 한다. 이 법은 AI 시스템을 리스크 수준에 따라 분류하며, 고위험 AI (의료, 교육 등)에 대해 엄격한 데이터 거버넌스, 투명성, 보안 요건을 부과한다.
OEDE AI Principles: OECD는 2019년 전 회원국의 합의로 AI 권고 원칙을 발표하고, 2024년에 이를 최신 기술 상황을 반영해 업데이트 했다. 이는 국제사회 최초의 AI 분야 정부 간 가이드라인으로, 혁신적인 개발을 장려하되, 인간의 권리와 민주적 가치를 존중해야한다는 큰 방향성을 제시한다. 특히, 인간 중심 가치 및 공정성 원칙에 프라이버시와 데이터 보호를 명시하여, AI 시스템이 개인의 사생활을 침해하지 말 것을 강조한다.
하지만 이러한 법률과 정책은 근본적으로 데이터 프라이버시를 보호하는 해결책이 될 수 없다. 과연 이를 기술적으로 해결하려는 시도들은 없었을까?
1.5.1 연합 학습 (Federated Learning)
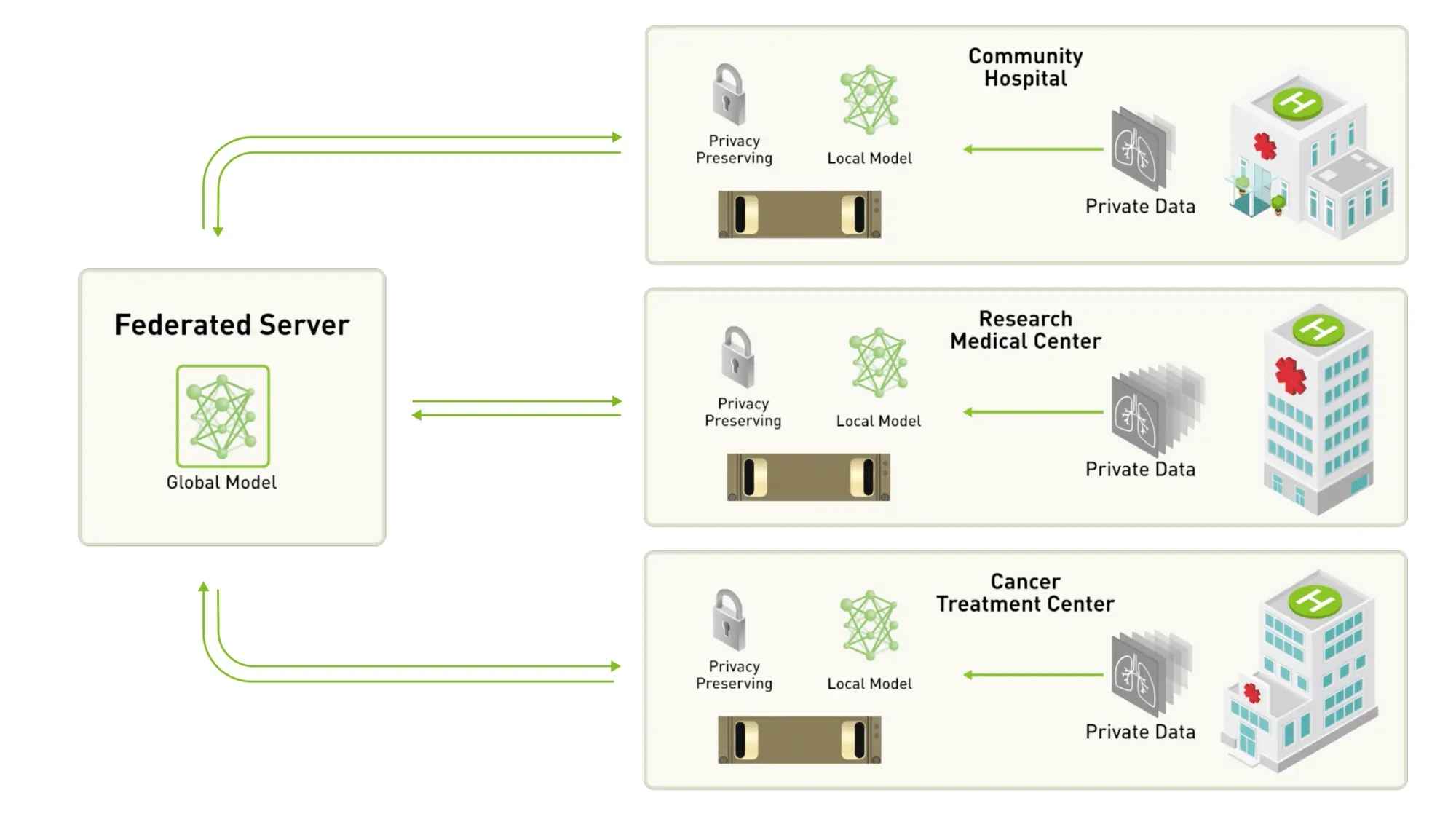
Source: Nvidia
연합 학습은 데이터를 사용자들의 로컬 장치에 보관한 채 AI 모델을 훈련하는 방식의 분산형 학습 알고리즘이다. 사용자들의 데이터는 모두 로컬에 존재하기 때문에, 중앙화된 기업이 이를 악용하거나 혹은 중앙 서버에서의 유출이 일어날 수 없어서 데이터 프라이버시가 안전하게 지켜질 수 있다.
작동 방식:
중앙 서버가 초기 모델을 클라이언트(스마트폰, 병원 시스템 등)에 전송
각 클라이언트가 자신의 데이터로 로컬에서 모델을 업데이트
업데이트된 모델 파라미터만 중앙 서버에 전송
서버는 여러 클라이언트의 업데이트를 집계하여 글로벌 모델을 갱신
이 과정을 여러 번 반복
실제 예시로는 구글의 Gboard나 엔비디아의 Clara가 있다. 구글의 Gboard는 사용자의 타이핑 습관에 따라 맞춤형 단어 추천 및 자동완성 기능을 제공한다. 키보드 입력 습관은 개인 정보가 많고 민감하기 때문에, 학습은 각 사용자의 로컬 기기에서 이루어지며, 업데이트된 파라미터만 중앙 서버로 전송된다. 엔비디아의 Clara는 병원, 연구소, 기업들이 민감한 헬스 케어 데이터로 함께 AI 모델을 안전하게 만들고 활용할 수 있도록 한다. 이는 병원 간 데이터가 유출되지 않으면서도 다기관 협업을 가능케 한다.
하지만 이러한 장점들에도 불구하고, 연합학습에는 서버-클라이언트간 모델 파라미터 전달에 비용이 발생하고, 모바일 기기들에게 로컬 계산 자원 부담이 있으며, 데이터가 분산되어있기 때문에 모델 품질 저하 가능성의 단점이 있다.
1.5.2 차등 프라이버시 (Differential Privacy)
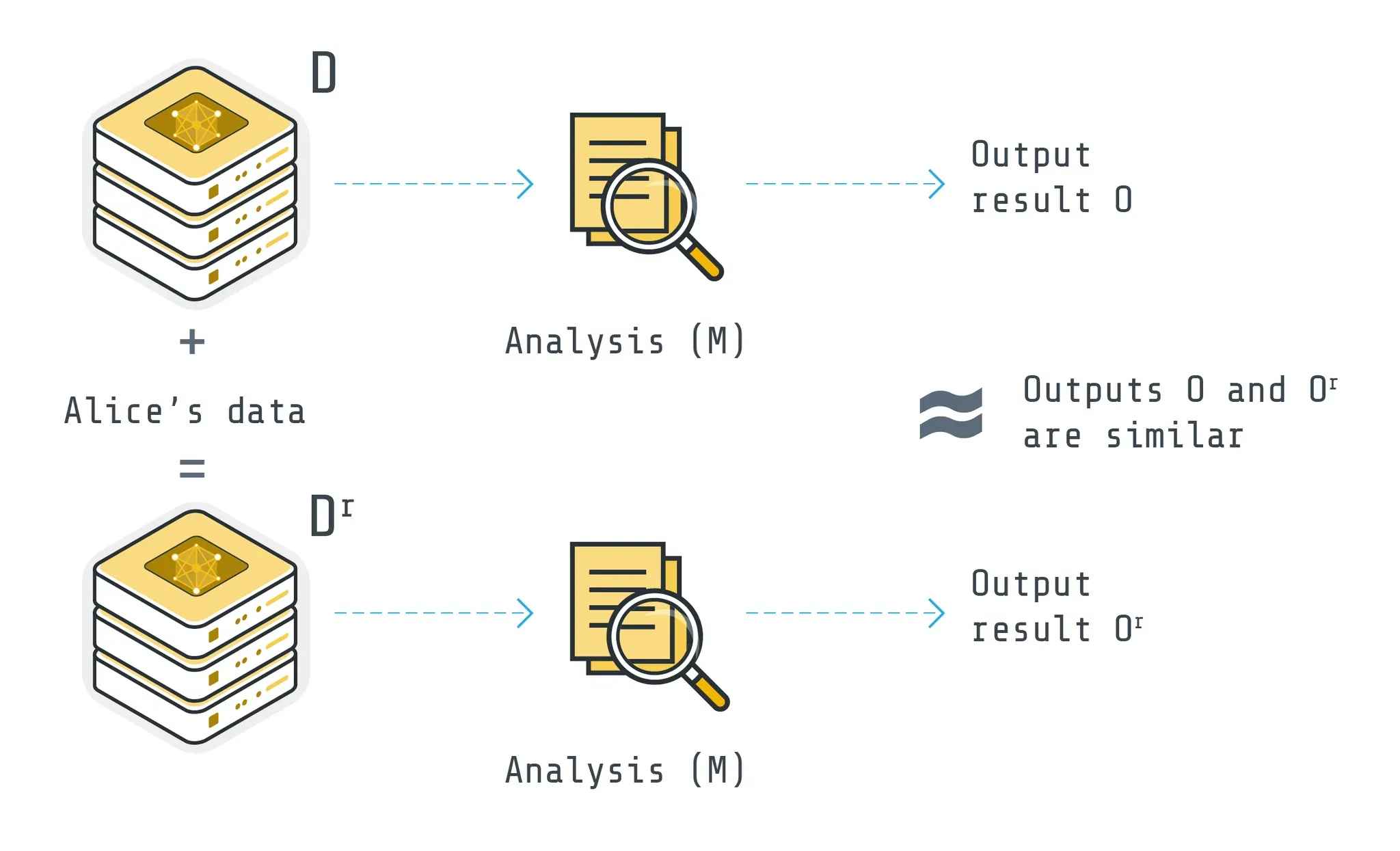
Source: flower.ai
차등 프라이버시는 어떤 데이터셋에서 개인 한 명의 정보 유무가 결과에 영향을 거의 미치지 않도록 노이즈를 추가하는 수학적인 방식이다. 이는 AI 모델의 훈련 결과나, 쿼리 응답에 의도적으로 미세한 무작위 변동을 주어 특정 개인의 데이터 기여도가 식별되지 못하게 한다. 차등 프라이버시 기술은 데이터의 유용성을 거의 유지하면서도 개인 특성을 감추어 프라이버시를 보장할 수 있는 것이다.
예를 들어 만약 지도 서비스에 차등 프라이버시를 도입한다고 가정해보자. 사용자의 실제 위치가 스타벅스인데, 차등 프라이버시는 사용자의 위치를 스타벅스 근처나 다른 카페로 바꿔서 서버에 보낸다. 수 많은 사람들의 데이터가 모이면, 차등 프라이버시로 인해 개개인의 위치는 알 수 없지만, 이 구역에 유동인구가 많다는 통계는 여전히 유효할 것이다. 차등 프라이버시는 2010년 후반대부터 상용 서비스에 도입되었는데, 애플은 iOS 사용 통계에, 미국 인구조사국은 통계 결과 공개에 이 기법을 활용했다.
실제로 LLM에서도 차등 프라이버시를 도입하려는 시도들이 최근들어 이루어지고 있다. 2024년부터 학계에 다양한 논문들 (”Fine-Tuning Large Language Models with User-Level Differential Privacy”, “Mind the Privacy Unit! User-Level Differential Privacy for Language Model Fine-Tuning”)이 보고되고 있으며, 구글 또한 차등 프라이버시 기법을 활용해 추론 단계에서 민감한 정보를 보호하면서 합성 데이터를 생성하는 방식을 도입하였다.
하지만, 차등 프라이버시는 데이터에 노이즈를 추가하기 때문에 정확도나 일반화 능력이 떨어질 수 있고, 노이즈 추가에 대한 추가적인 계산 비용이 증가하며, 결정적으로 노이즈의 크기를 적절히 조절하는 것이 중요한데, 이를 맞추기가 쉽지 않아 실제 서비스에 적용이 쉽지 않다는 단점이 있다.
위에서 연합 학습과 차등 프라이버시와 같은 데이터 프라이버시를 보호할 수 있는 기술들을 살펴보았지만, 아직 한 가지 가장 중요한 솔루션을 설명하지 않았다. 바로 암호학을 활용한 연산기법들이다. 이는 데이터를 암호화된 상태로 AI 모델의 학습과 추론에 활용할 수 있게 한다. 대표적인 예시로 ZK, MPC, TEE, 그리고 FHE가 있다.
ZK: 상대방에게 정보를 공개하지 않고서도 특정 주장이 올바르다는 것을 증명할 수 있는 암호학적 기법이다.
MPC: 여러 참여자가 각자의 데이터를 공유하지 않으면서도, 공동으로 계산을 수행하여 결과만 얻을 수 있게하는 암호학적 프로토콜이다.
TEE: 하드웨어 프로세서 내의 별도 보호 영역에서 코드와 데이터를 안전하게 실행하는 하드웨어 기반의 기술이다.
FHE: 암호화된 데이터에 대해 직접 계산을 수행할 수 있게하는 방식으로, 계산 결과를 복호화하면 평문에서의 계산 결과와 동일하게 된다.
이러한 기술들은 AI 모델의 학습과 추론에서 사용자들의 중요하거나 민감한 데이터를 공개하지 않으면서도 연산을 수행할 수 있어, AI 데이터 프라이버시에 대한 핵심 솔루션으로 주목받고 있다.

Source: Nillion
암호학이 AI 산업 내에서 데이터를 안전하게 관리하고, 연산에 사용할 수 있도록 하는 것을 알아보았다. 하지만 암호학 그 자체로는 AI 데이터 프라이버시의 완벽한 솔루션이 될 수 없다. 만약 특정 LLM 서비스 기업이 암호학을 활용하여 사용자들의 데이터를 관리하고 연산한다고 하여도, 이러한 행위가 결국 중앙화된 서버에서만 이루어진다면, 사용자들은 이를 검증할 방법이 없다. 즉, 자신의 데이터가 안전하게 처리되고 있는지에 대해서는 해당 기업을 전적으로 신뢰해야하며, 이는 AI 데이터 처리에 암호학이 쓰이든 안쓰이든 똑같은 결과를 낳는다.
이를 간단하게 해결할 수 있는 방법이 있다. 바로 블록체인의 도입이다. 블록체인은 탈중앙화되고 검증가능한 데이터베이스로써, 암호화된 데이터 연산 기술과 결합되었을 때 사용자들이 안심하고 사용할 수 있는 AI 데이터 플랫폼으로 거듭날 수 있다.
사용자들은 자신들의 데이터가 안전하게 관리되고 연산되는지 블록체인을 통해 투명하게 모니터링하고, 검증할 수 있으며, 사용자들의 요청을 받아 암호화 기술을 활용하여 데이터를 연산하는 서버들은 자신이 기여한만큼 인센티브를 공정하게 받을 수 있다. 이것이 바로 닐리언(Nillion)이 나아가고자 하는 방향이다.
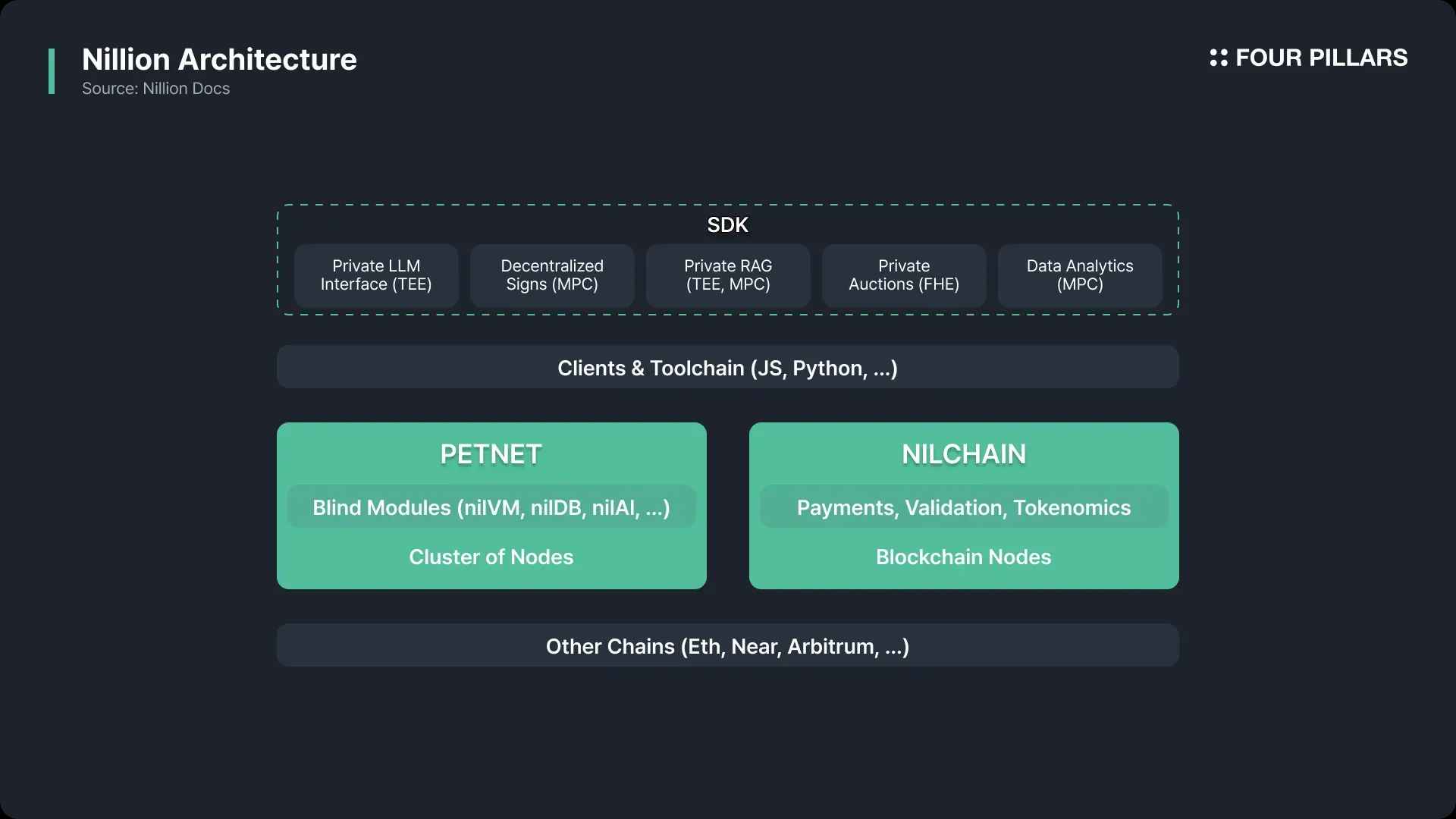
Source: Nillion
닐리언의 구조는 크게 Petnet과 NilChain 두 개로 구성되어있다. Petnet은 탈중앙 노드들이 사용자들의 요청을 받아 데이터를 암호화하고 연산하는 네트워크이며 (블록체인이 아니다), NilChain은 코스모스 SDK 기반의 블록체인으로, 트랜잭션의 기록, 연산의 검증, 참여자들 사이의 페이먼트, 거버넌스 등 다양한 기능을 수행한다. 마치 IPFS가 실제 파일의 탈중앙 스토리지 역할을 하고, 파일코인이 이 위에서 거버넌스, 인센티브, 검증의 역할을 하듯이, 닐리언에서도 Petnet이 암호화된 데이터의 연산 작업을 직접 수행하고, NilChain이 블록체인으로써 투명성, 불변성, 탈중앙성, 보안성 등의 역할을 제공하는 것이다.
닐리언에 대해서 더 자세한 내용은 이전에 Steve가 작성한 “The Most Important Infra of AI Agent Personalization: Nillion”을 참고하길 바라며, 본 글에선 닐리언 팀의 배경과 주요 기술에 대해 더 자세히 살펴볼 것이다.
2.3.1 주요 멤버 소개
Andrew Masanto (CSO): 헤데라 해시그래프와 리저브 프로토콜의 공동 설립에 참여하여 두 번의 유니콘 스타트업을 성공시킨 연쇄 창업가이다.
Alex Page (CEO): 골드만삭스 출신의 금융 전문가로, 스포츠 영양 보충제 회사 Sports Food Nutirtion과 간편 건강간식 브랜드 Weekday Warriors를 공동 창업한 경험이 있다.
Miguel de Vega (Chief Scientific Officer): 블록체인, 암호학, 머신러닝 분야에서의 기술 전문가로, 데이터 최적화 및 보안 관련 특허를 30건 이상 출원한 경력을 가지고 있다. 닐리언의 핵심 기술인 Nil Message Compute를 발명한 수학자이다.
Conrad Whelan (Founding CTO): 우버의 창립 엔지니어 출신으로, 현재 엔지니어링 팀을 이끌고 있다.
Andrew Yeoh (CMO): UBS, 로스차일드 투자은행에서 애널리스트로 근무한 경험이 있으며, Alex Page와 피트니스 식품 스타트업을 공동 창업한 바가 있다. 헤데라 해시그래프에도 초기부터 참여하여 블록체인 생태계의 경험을 쌓고, 닐리언에선 CMO로서 마케팅 전략과 생태계 확장을 주도하고 있다.
Mark McDermott (COO): 디지털 미디어 스타트업 GoShow를 창업하여 CEO의 경험이 있으며, 나이키의 유럽 혁신 조직에서 파트너십 총괄을 맡은 경험이 있다.
2.3.2 주요 기술들
닐리언팀은 비지니스에서의 화려한 이력을 바탕으로, 과거부터 학술적인 논문을 지속적으로 작성해온 크립토 산업에서 비지니스와 학구적인 부분에 동시에 뛰어난 몇 안되는 팀이다.
연구적인 부분을 살펴보면, 2023년 “Technical Report on Decentralized Multifactor Authentication”부터 최근 “Wave Hello to Privacy: Efficient Mixed-Mode MPC using Wavelet Transforms”까지, 닐리언 팀은 AI, 암호학, 프라이버시 분야에서 연구를 지속적으로 수행해왔다.
Technical Report on Decentralized Multifactor Authentication (Link)
의료 기록, 금융 거래 등 민감한 데이터를 보호하기 위해선 중앙 서버가 아닌 여러 곳에 데이터를 분산 저장하는 분산 인증 시스템이 필요하다. 기존의 중앙집중형 인증은 단일 실패점 문제가 존재한다. MFA는 비밀번호, 모바일 기기, 생체인식 등 여러 인증 요소를 결합하여 보안을 강화하는 방법으로, 웹3 생태계에선 오직 개인 키 소유 증명만으로 인증하는 한계가 있어 추가적인 보안 요소가 요구된다.
이 논문은 중앙화된 인증 시스템의 단점을 극복하기 위해, 분산 환경에서 MFA를 구현한 기술적 접근법을 다루며, 특히 MPC 기반의 분산 인증 프로토콜을 제시한다. MFA에 MPC를 적용하면 사용자들은 인증 정보를 직접 노출하지 않고서도 여러 서버가 공동으로 인증 과정을 수행할 수 있다. 닐리언은 통신을 최소화한 새로운 프로토콜의 설계로 사용자 대기 시간을 감소시키며, 기존의 비밀번호나 생체인식 뿐만 아니라, 이메일, 전화, 블록체인 지갑 등 다양한 인증 요소를 통합하여 사용할 수 있도록 하는 MFA 시스템을 제시한다.
Technical Report on Threshold ECDSA in the Preprocessing Setup (Link) 다수의 사용자들이 함께 서명할 수 있는 threshold ECDSA 방식은 널리 사용되고 있지만, 단일 실패 지점이나 악의적인 서명자들의 협력에 취약할 수 있다. 닐리언은 이를 해결하기 위해 다음과 같은 새로운 threshold ECDSA 서명 프로토콜을 제안한다.
클라이언트-서버 모델의 하이브리드 접근: 클라이언트와 서명자 간 역할을 분담하여, 클라이언트는 단순히 메시지를 전송하고, 서명자들은 사전처리를 통해 미리 계산한 암호화된 자료로 서명을 생성한다.
MPC 프로토콜 도입: MPC 기법을 활용하여 서명자들이 자신의 키 쉐어 정보만 가지고 계산을 수행하고, 클라이언트가 소유한 암호화 비밀 키로 최종 검증을 수행함으로써, 악의적인 서명자들이 협력한다고 하여도, 공격을 방지할 수 있다.
More efficient comparison protocols for MPC (Link) MPC 프로토콜의 한 종류로 두 참여자들이 각자의 비밀값을 서로 공개하지 않고서 비교하는 작업인 비교 프로토콜(comparison protocol)이 있는데, 기존 비교 프로토콜들은 온라인 통신 비용과 라운드 수가 많이 소모되었으며, 특히 입력 비트수가 늘어날수록 성능이 저하됐다. 닐리언은 이를 해결하기 위해 시프트된 비트 분해(shifted bit decomposition) 및 프리픽스 곱셉(prefix multiplication)을 통해 더 나은 성능을 이끌어 낸다.
Technical Report on Secure Truncation with Applications to LLM Quantization (Link)
인공지능 모델을 더 작고 빠르게 만들기 위해, 계산 도중에 숫자의 자릿수를 줄이는 절단(truncation) 방법을 사용하면 메모리를 절약할 수 있다. 하지만, 기존의 절단 방법은 오히려 보안을 위해 많은 추가 비트를 사용해야해서, 계산을 느리게 하는 역설적인 결과를 낳았다. 닐리언 팀은 이를 MPC를 도입한 연산을 통해 보안성을 유지하면서도 계산의 복잡성을 줄이는 새로운 기술을 제시한다.
Ripple: Accelerating Programmable Bootstraps for FHE with Wavelet Approximations (Link)
기존 FHE 체계는 기본 연산이 덧셈과 곱셈으로 제한되어 있어, 비선형 함수의 계산에 어려움이 있다. 이를 위해서 룩업 테이블을 활용할 수 있으나, 입력 비트 수가 증가하면 룩업테이블의 크기가 매우 커져 실행 시간과 메모리 사용량이 크게 증가한다.
닐리언은 델라웨어 대학교 연구팀과 함께 Ripple 프레임워크를 제시하는데, 이들은 discrete wavelet transform이라는 기술을 통해 룩업테이블의 크기를 줄이면서도 높은 정확도를 유지하는 것을 목표로 한다.
Curl: Private LLMs through Wavelet-Encoded Look-Up Tables (Link)
기존 LLM들은 서론에서 말했듯이 데이터 프라이버시의 문제가 있다. 이를 해결하기 위해 MPC를 LLM에 적용해도, 비선형 함수의 근사 과정에서 오차나 통신 비용이 많이 발생한다는 문제가 있다. 닐리언 팀은 University of California Irvine과 메타(Meta)와의 협업을 통해 Curl을 소개한다. Curl은 Ripple 논문과 마찬가지로 discrete wavelet transform 방법을 활용해 룩업 테이블을 압축하고, 이를 통해 비선형 함수 근사를 효율적으로 수행한다.
Wave Hello to Privacy: Efficient Mixed-Mode MPC using Wavelet Transforms (Link)
해당 논문 또한 Curl 논문과 비슷하게 MPC에 discrete wavelet transform 방법을 활용하여 머신러닝에 흔히 사용하는 비선형 함수들을 높은 정확도로 평가할 수 있는 방법을 제시한다.
프로메테우스가 신의 불을 인류에게 전함으로써 문명의 빛과 어둠을 동시에 가져온 것처럼, AI는 엄청난 혁신과 부를 선사하지만, 그 이면에는 통제되지 않은 데이터 프라이버시의 위험이라는 그림자가 드리워져있다. 닐리언이 뛰어난 팀과 연구실력을 기반으로, 암호학과 블록체인을 통해 인류가 AI 시대에서 안전하고 투명한 미래로 나아갈 길을 열어줄 수 있길 바란다.
관련 아티클, 뉴스, 트윗 등 :
“The Most Important Infra of AI Agent Personalization: Nillion” by Four Pillars